Someone on twitter once remarked that law cannot be reduced to algorithm; he was commenting on my article “Alchemy and Algorithmic Lawyers”, he said that it was “impossible”. As a means of substantiating his claim he added that he had more than twenty years experience as a scientist and programmer. Personally I prefer to not make very grand, generalized claims of impossibility. Simply because impossibility is a fallacy that people create as an opium to pacify our innate desire to be different. It is purely a means of making it easier to ingest the status quo, thereby making it slightly more palatable. Fortunately he is wrong, Law can be reduced to algorithm, in fact the very substratum of law and its application is inherently algorithmic in any event. Laws and Algorithms are architected on identical paradigms or at the very least very consubstantial ones. It is indeed a fact that how “traditional” law is architected is devoid of any computational or math-based processes. I would like to put an emphasis on the word “traditional” however, because as I have shared before in previous blogs, I have succeeded in delineating law into a series of computations for the purposes of algorithm-based machine learning. “Big Law” (derivative of Big Data) is also growing rapidly and is beginning to uncover and illustrate the algorithmic acuteness of law.
Anyway, enough waffling, let us get down to the blade runner and how his conviction of Culpable Homicide (or man slaughter) instead of Murder (Dolus Eventualis) has an effect on Data Science. To jog your memory, Oscar Pistorius is the athlete who shot and killed his girlfriend through a locked bathroom door on Valentines Day. He was convicted of culpable homicide, and sentenced to five years in prison in October last year. He is expected to be released on 21 August and placed under house arrest as per a recommendation from the Department of Correctional Services. The state appealed the decision of the High Court and the Supreme Court of Appeal will hear the matter in November.
Dolus Eventualis (D.E) is where the accused foresees the real possibility of death and acts reckless to that possibility or reconciles himself with it. D.E speaks to the mental state of the accused at the time of the alleged criminal act (a pivotal aspect in its general interpretation and in Pistorius’ case). Therefore D.E can be broken up into two aspects, foreseeing a real possibility of death and reconciling oneself to that possibility. I will not delve into an in-depth legal analysis of D.E with regard to the Pistorius case because such analyses have been done exhaustively.
This article serves the purpose of merely illustrating, at a very simple level, how we go about building Analytic Models for legal principles like Dolus Eventualis. It is also an attempt to quell any suspicions (among scientists and programmers with 20 years of experience) of impossibility regarding advanced algorithmic law. It is purely an abstract account of how we build predictive and classification models for contentious legal rules and decisions. This is done so that ultimately what you have is legal principles being validated and tested for statistically by computational means. It adds efficacy to the need for certainty and consistency within the operation of law.
There are areas of this article that Data Scientists will understand and Lawyers won’t, there are also technical areas of law that Data Scientists may not fully grasp. I would ask that where you do not understand, to try contextualize the basic premise of what you are reading into your respective field. Before reading this article further, I would urge the reader to read my previous article, “Data Science: The numbers game law almost lost”. Lest you express great shock at the ease at which I speak of math- based numeric values vis a vis case law and other legal data.
As stated before (ad nauseam), we have developed a math-based metric conversion system that converts raw legal data into coherent and stratified numerical values. Applying this conversion system is the first step in classifying a principle like D.E. Our system has a built-in ETL (extract, transform, load) methodology that is applied to all raw legal data relating to D.E. At the risk of revealing our trade secrets, I will briefly explain the ETL process. When ETL is applied to the case law dealing with D.E, the facts of all those cases are extracted and the values of the correlating outcomes are imputed onto those facts. So that fact “x” will have outcome “y”, facts can have multiple outcomes, and therefore multiple outcome values. The process is useful because one can segment all “y” outcomes and compute their correlation with all “x” facts, sometimes in totally different areas of law, which makes exploratory analytics in legal data much easier. That is just a rough summation of the ETL process our conversion system goes through. It is an iterative process and includes a number of Analytic models that use genetic algorithms. When the conversion system is applied to case law it breaks-up the facts and the subsequent rulings thereof into very small particles and factual permutations (fragmentation). The system then analyses and weights those particles and factual permutations according to the legal principle set in the subsequent ruling. For example, the case of Humphreys vs S (2013) is a very important case with regard to D.E., in this case, all the actions of the mini bus taxi driver leading up to and after the collision with the train will be fragmented into particles and analyzed algorithmically and each particle will be attributed a calculable numerical value. For instance, the driver overtaking a line of stationary vehicles will be given a weight. Note that the weight is stratified according to its practical legal implication. For example, the court found that the mini bus taxi driver overtaking those vehicles was of “peripheral relevance”; therefore this permutation will be given a lesser value in relation to the other permutations. This process makes producing thresholds for the purposes of machine learning possible.
The next step our conversion system goes through is calculating the sum of the numerical values of all the cases that have ever dealt with D.E (and their permutations). This will serve as what we call a “quantum”. All basic math functions that the conversion system applies (addition, multiplication, subtraction, division) will take place strictly within the parameters of this quantum. The calculations within this quantum are based on the premise of duality and that of equal and opposite reactions. That is to say, when it subtracts, an opposite and equal addition will be made, when it adds, an equal and opposite subtraction will be made; the quantum is therefore never exceeded.
This is done so that what we at Gotham Analytics call “Combative Analytics” can be applied. We use the term “combative” because in legal matters there is always a dispute between parties where two divergent interests are competing against one another. Either between a plaintiff and a defendant or the state and the accused, that is precisely why the conversion system works on the premise of duality when producing the values. You cannot produce coherent values where an objective quantum is undermined or is not adequately maintained. Therefore the quantum can best be described as the referee in the dispute or (at the risk of being blasphemous) a judge.
I find that fragmentation allows for the quantification and discovery of very subtle insights into legal data. For instance, one of the issues the court elucidates on in the Humphreys case is the conflation of the test for D.E with that of aggravated or conscious negligence. This could be one of the points the Supreme Court of Appeal relies on in making its judgement, it would therefore be prudent to quantify it when building any Analytic model for D.E. Once the conversion is complete, the numeric values can be used for algorithm-based machine learning
A myriad of machine learners are used for classification purposes, all taught D.E at varying degrees based on legal data. Three models are built, the first for classifying strictly numerical values, weights and thresholds (there is a difference), it includes Neural Networks, Regressions and a few Discriminative classifiers. The second model will analyze more varied data, with both numeric and other attributes, some very surprising (for example dates for the purposes of time series algorithms), and this second model includes tree induction, correlation, segmentation, association rules and more machine learners. The third will amalgamate the results of the first and second models into a single grand model. It will include simulations, rule induction algorithms, Meta learning schemes and many other Analytic functions. We create an ensemble of machines and sub-processes feeding data to each other back and forth, converging and deviating continually.
Once the computations of the first three models are complete; requirements, factors for consideration and other legal reasoning summations can be reduced to a series of calculable numeric thresholds. Exceeding or falling short of these thresholds informs the degree to which a certain requirement in the courts’ reasoning has been satisfied or not. This adds mathematical precision to judgments in a consistent, un-biased and scientifically objective manner. It is these thresholds that form the basis of many of our predictive and automated compliance models. Numeric thresholds for the D.E requirements of foreseeing a real possibility of death and reconciling oneself to that possibility can now be produced using the results of the machine learners. Building numeric thresholds for Mens Rea enquiries (where the law makes an enquiry into the cognitive state of the accused at the time of the commissioning of the crime) is quite a feat. Mathematically quantifying what the courts deem to be the prescribed mental state of the accused for D.E to succeed of fail is a jurisprudential breakthrough to say the least.
It is even possible for certain algorithms to give a formula for calculating whether Oscar’s conduct was reasonable and commensurate to the perceived imminent threat, which is a fundamental element of the reliance on private or putative self defence(which was one of Oscar’s defences). The requirements of Dolus Eventualis can be delineated into math-based formulas to be applied to the facts of any matter. We can measure mathematically how far Oscar exceeded the bounds of reasonableness in his attack as a result of the perceived threat. We can even produce numerical value thresholds to calculate how divergent his actual conduct was from the legally prescribed conduct of a person who foresees a real possibility of death. I often marvel at how Data Science platitudes like searching for an outlier or anomaly detection techniques in very basic Analytics software can be the difference between whether someone will be found guilty of murder or not. Unfortunately most in the legal fraternity do not know this, which is tragic. How something as basic as a standard deviation can be used as an argument in mitigation or aggravation of sentence and indeed used by a judge in handing down a sentence. Time and time again I see how something so facile in the field of advanced Analytics can be so crucial in the veracity of legal outcomes like that of the Pistorius case.
I am also perplexed at how the law can speak about a “balance of probabilities” as a burden of proof in civil matters and not be at least mildly interested in statistical probability theorems. One scholar said of the Bayesian theorem that it is to the theory of probability what Pythagoras is to geometry. I am not saying Naïve Bayes is an all encompassing “cure-all”, because it is not, all I am saying is that at least use it as a tool, as a guideline to the sanctity of human discretion. As a law student studying case law the phrase, ‘a balancing approach” is hammered into your head when interpreting a judges’ decision. Judges regularly employ balancing approaches, especially where divergent interests are being considered and calculating which interest is more reasonable based on the facts is necessitated.
The court is tasked with the huge responsibility of finding some sort of equilibrium between two opposing arguments or interests, and yet they do not consider seeking a math based equilibrium point on a basic line graph giving a statistical account of both the parties’ interests.
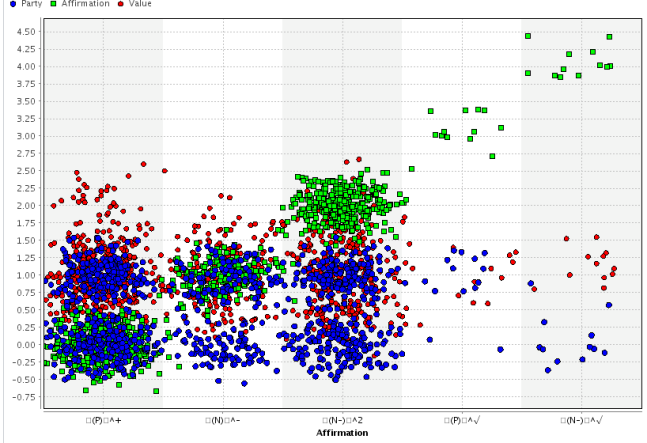
Below is a small part of a formula created from the results of a regression algorithm used in a classification model. It measured the respective thresholds each of the parties scored in relation to the principle of Estoppel under Administrative Law. The formula was extracted from the well known case of City of Tshwane vs. RPM Bricks. The Model is as robust and statistically accurate as possible; it is simply a mathematical account of the precedent the case set:
– 0.6182529010134109 * (-0.28122611157540334 * Party Value + 0.8082030429003213 * Value)+ 0.45123082530789793 * (-0.03263760806368616 * Party Value + 0.8082030429003213 * Value)- 0.6159847913194462 * (-0.28122611157540334 * Party Value – 0.20673012012673037 * Value)+ 0.45347425335361813 * (-0.03263760806368616 * Party Value – 0.20673012012673037 * Value)
“Party value” and “Value” are the values that our conversion system would produce. A formula such as this could be the summation of every piece of reported and unreported case law, every Ratio Decidendi, every Obiter Dictum, every facet of a courts’ reasoning, every single relevant legislative provision reduced to a coherent formula. Now, Analytics practitioners know that something like this is rather elementary, these are basic entry-level Analytics. That said however, when applied to the field of Law, it becomes the supreme panacea to all legal uncertainty.
Sure, Data Science is prone to error, like any other science or art, but so is law. If Law was impervious to error there would be no such thing as appeal. The point is to formulate means of analysis that are the most deviant from the inevitability of error. What was extremely worrying about the Pistorius case was really the proliferation of the view that people with money can get away with murder, literally. Perhaps society can have greater confidence in a justice system that uses mathematical and statistical aides. Aides that are devoid of subjective susceptibilities and dispositions.
Whether he is guilty of murder (Dolus Eventualis) or not from a Data Science point of view, we will not say, because that piece of information from us is proprietary. Whatever the Supreme Court decides, Legal Practitioners, Judges, even Commercial entities, and especially the general public should know that Data Science can provide a transcendent system of justice. A system of justice that is truly impartial, precise, efficient and expedient. One that cares nothing about your net-worth, influence or celebrity status. A justice system that the world has never had the privilege of seeing before, until now. That, is my Magnum Opus.